By: Reid Brosko
Back in 2019, our team developed “McCracken,” an on-premises hash cracking rig. This project was born from necessity, curiosity, and the drive to give our Red Team a significant advantage in security engagements. At the time, we built the rig on a $5,000 budget, outfitted it with GTX 1080s, and tuned it to maximize every possible hash per second. The results were immediate and impactful, allowing us to crack hashes that were previously impractical during live engagements.
Fast forward to today, and the demands have only increased, with more simultaneous Red Team engagements, more captured hashes, and more advanced defensive monitoring in client environments. Scalability became our bottleneck, sending us back to the drawing board to engineer a more resilient, distributed, and automated approach to hash cracking.
Lessons Learned: Hardware Failures and Upgrades
Running high-performance computing rigs inevitably leads to hardware wear. Over the years, we lost two GPUs to fan failures. Instead of replacing them with like-for-like models, we opted to modernize our setup. We upgraded those two GPU losses with NVIDIA RTX 4070 TI Supers and added two additional NVIDIA RTX 4070 TI Supers.
The upgrade delivered a significant performance boost. We saw improvements not just in raw cracking speed, but also in power efficiency, heat management, and overall hardware longevity. This was the first crucial step toward building a rig that wasn’t just fast, but scalable. Effective hash cracking requires a robust hardware foundation that can withstand continuous, intensive workloads.
Evolving Beyond a Single Instance: Enter Hashtopolis, A Distributed Approach
Originally, McCracken ran as a traditional hashcat instance. While effective initially, as the team grew and workloads increased, we needed a better way to manage and distribute tasks. That’s where Hashtopolis came in, a client-server framework designed specifically for distributing hashcat tasks across multiple systems. It features a customizable Python agent to adapt to various needs and a PHP-based server that provides both an Admin GUI and an Agent Connection Point. Communication between components runs over HTTP(S) using a JSON dialect designed specifically for hash cracking.
The key benefits of this new distributed hash cracking architecture included:
- Scalability – We can now distribute jobs across multiple rigs.
- Multi-user support – Multiple team members can submit and manage hash cracking tasks simultaneously without conflict.
- Prioritized tasking – The system automatically queues and assigns jobs based on urgency, ensuring critical tasks are handled first.
- Enhanced Portability – Even on restricted networks, agents can communicate cleanly over HTTP(S).
This wasn’t just an upgrade, but it was a transformation of our hash cracking methodology.
The New Architecture: Modular Hash Cracking Agents
Instead of relying on a single massive rig, we deployed three separate “Agents”, each functioning as a self-contained cracking node. Every agent includes:
- Motherboard: Biostar TZ590-BTC Duo
- CPU: Intel® Core™ i5-11400
- RAM: Crucial Pro DDR4 64GB (3200 MHz)
- Storage: Samsung 990 PRO 4TB NVMe SSD (with heatsink)
- Power: Seasonic PRIME Ultra 1000W 80 PLUS Titanium
- GPUs: A mix of surviving 1080s and upgraded RTX 4070 TI Supers
This modular design gives us redundancy (no single point of failure), easier upgrades, and the ability to assign jobs to the best-suited agent.
Measuring the Performance Gains
The new Hashtopolis-enabled “McCracken 2.0” isn’t just more scalable, it’s measurably faster:
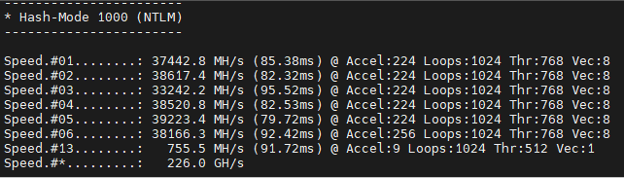
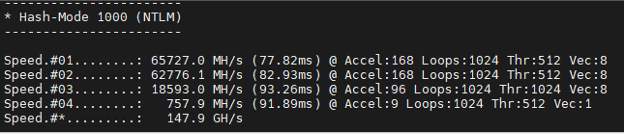
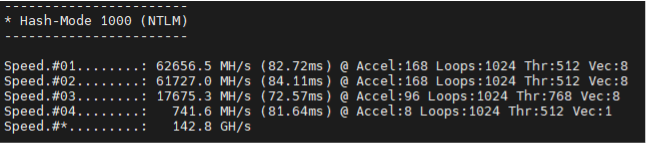
- NTLM (Hashmode 1000):
- Before: 197 GH/s
- Now: 516.7 GH/s
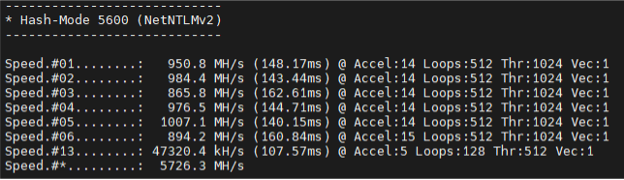
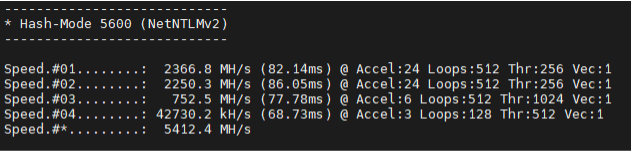
- NetNTLMv2 (Hashmode 5600):
- Before: 10.49 GH/s
- Now: 16.675 GH/s

- Kerberos 5, etype 23, TGS-REP (Hashmode 13100):
- Before: 1917.6 MH/s
- Now: 8.644 GH/s
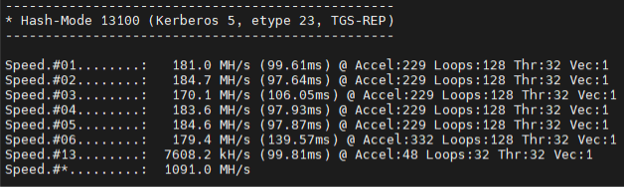


As the data shows, we achieved more than double the throughput in some cases. For context, what used to take hours can now be reduced to minutes—directly improving our efficiency and effectiveness during live operations.
Why Advanced Hash Cracking Matters for Red Teaming
In any offensive security engagement, time is everything. The faster we can turn around cracked hashes, the faster we can pivot, escalate privileges, or prove impact to the client. With Hashtopolis and modular cracking agents, our team can:
- Allow multiple operators to submit jobs simultaneously without collisions or bottlenecks.
- Prioritize time-sensitive jobs, such as cracking domain-level NTLM over low-value local accounts.
- Automate recurring cracking workflows to streamline the entire hash cracking process.
- Scale horizontally by adding more agents as budgets (and workload demands) increase.
We have successfully evolved what used to be a static resource into a dynamic cracking platform for modern Red Team operations.
The Future of Our Hash Cracking Platform
What began as an internal side project in 2019 has now become a mission-critical Red Team asset. Hashtopolis has given us not just power, but flexibility—and the new modular architecture sets us up for future growth. Our next steps include expanding beyond three agents, experimenting with mixed GPU generations, and potentially containerizing some of our cracking workflows for even easier deployment. The world of cybersecurity and Red Teaming is in constant motion, and our hash cracking capabilities will continue to evolve right alongside it.
Curious about how advanced hash cracking can elevate your Red Team operations? Reach out today to explore how our expertise and innovative solutions can help you stay ahead in cybersecurity.